

La société de conseil aux entreprises Gartner a récemment publié un rapport où les données massives comptent parmi les thèmes suscitant les attentes les plus démesurées[1]. Alors que la théorie et la pratique en la matière sont encore rudimentaires, plusieurs consultants n’ont que ce mot à la bouche pour vendre de nouveaux matériels et logiciels capables, selon eux, de tirer des renseignements plus fins de la masse des données collectées. Par rapport à d’autres branches, comme l’industrie des biens de consommation ou le commerce, celle des assurances se montre plus réservée. Elle attend de voir si les contradictions de la nouvelle évolution technologique peuvent être résolues et comment.
Les données, cœur de métier des assureurs
Les assurances remplissent un rôle crucial d’alerte précoce envers la société. Elles anticipent l’avenir sur la base de données antérieures et attirent ainsi l’attention sur l’évolution des risques attendus. Leurs évaluations sont des processus itératifs qui impliquent la saisie et l’analyse d’innombrables données pour mieux en comprendre la substance et mieux les mesurer. Parallèlement, les assureurs organisent la compensation des risques à travers différents systèmes collectifs pour rendre le risque individuel supportable.Cela étant, il peut sembler paradoxal, à première vue, que les assureurs ne figurent pas parmi les pionniers en matière de technologie et de gestion des données. L’extrême densité de la réglementation aboutit, en outre, à ce que de nombreuses compagnies d’assurance travaillent encore avec des produits et processus basés sur d’anciens systèmes informatiques. Le secteur ne néglige, toutefois, pas les progrès toujours plus rapides de la technologie. Les cadres dirigeants y perçoivent, en effet, de plus en plus de nouvelles possibilités d’affaires.
Nouveaux modèles d’affaires, nouveaux produits, nouveaux marchés?
Les assureurs ne sont qu’au début du voyage dans les données massives, mais ils sont déjà confrontés à une série d’occasions et de défis susceptibles de déclencher un processus de transformation fondamentale. Ainsi, de nombreuses sociétés d’assurance prévoient d’investir davantage dans les données massives et les systèmes d’analyse appropriés en 2014[2]. Les principaux objectifs sont ici d’identifier les problèmes de conformité («compliance», par exemple en cas de tentative de fraude), d’augmenter la productivité et de mettre au point de nouveaux produits[3]. Les applications envisagées sont illimitées. L’analyse des sites consultés pour éviter les fraudes internes ainsi que celle des réseaux sociaux pour mieux comprendre la clientèle et optimiser les mesures de marketing ne sont qu’une première étape. Le potentiel majeur des données massives réside en effet dans l’assurance-vie, l’assurance-maladie privée et l’assurance-automobile. À quelle vitesse et à quelle fréquence tel assuré roule-t-il? Fait-il régulièrement du sport et se nourrit-il sainement? Des capteurs fixés sur le corps, dans une auto ou sur tout autre objet fournissent des données biologiques et comportementales. Leur analyse approfondie permet de mieux cerner les comportements de la clientèle et d’en prédire les risques. Parallèlement, il se constitue de nouveaux écosystèmes de produits et services qui consolident les marchés, toutes branches confondues. Le principal défi qu’affrontent actuellement les assureurs est l’analyse des données massives. Quels sont les algorithmes, modèles et théories capables de donner un sens à cette masse et de mettre en évidence des modèles encore inconnus? C’est dans ces connaissances inédites que réside la plus-value importante des données massives.
Les données massives dans la pratique: la télématique embarquée
L’un des domaines où les données massives suscitent le plus d’espoir est le recours à la télématique pour saisir et analyser les informations fournies en temps réel par les automobiles. Données GPS, usage des freins, durée, longueur et type de chaque trajet sont envoyés toutes les quelques secondes à la compagnie d’assurance par une boîte noire embarquée et par le réseau de téléphonie mobile. La compagnie dépouille les données, adapte la prime d’assurance de façon dynamique et met le dépouillement à disposition du client. Ce processus d’échange constant permet à l’assuré d’influencer sensiblement le montant de ses primes («pay how you drive»). Les États-Unis, l’Italie et la Grande-Bretagne connaissent déjà des exemples réussis en ce domaine, accompagnés fréquemment de modèles d’affaires originaux et particulièrement légers. On estime que les offres télématiques correspondront, en Europe, à 50 milliards d’euros de primes d’ici la fin de la décennie[4].
À l’avantage de tous les participants
Les avantages de ces modèles sont évidents. D’une part, ils provoquent un certain effet d’autosélection, du fait qu’ils interpellent avant tout les conducteurs fiables, qui devraient payer des primes supérieures si une telle technologie n’existait pas. De l’autre, les assureurs peuvent nettement mieux évaluer les risques et donc calculer plus exactement les primes. En outre, ils exercent une action préventive – et non seulement économique – en incitant les preneurs d’assurance à conduire de façon plus sûre. La technologie simplifie également la détection des fraudes et contribue à abaisser les coûts. D’un autre côté, les fournisseurs sont confrontés à deux risques: a) que l’effet préventif cité fasse fondre le volume des primes, b) que cet effort de transparence rétrécisse les marges des uns et des autres, alors que l’on peut encore les qualifier de correctes à l’heure qu’il est. Les modèles de tarification liés au comportement peuvent être transposés facilement à d’autres domaines de l’existence, comme la santé ou le logement («pay how you live»). Ils sont compatibles avec certaines tendances fondamentales de l’évolution de la société, telles l’individualisme ou les réseaux sociaux[5]. Ces modèles permettent de nouvelles formes de communication et d’interaction entre assureurs et assurés. Le côté abstrait de la police d’assurance devient vécu, et ce non seulement en cas de sinistre, mais tout le long du «customer journey»[6]. Ces nouvelles interactions induisent aussi une perception altérée des «customer values», donc des valeurs qu’un assuré ressent dans sa relation avec son assureur. C’est pourquoi cette grandeur sera désormais un facteur de succès stratégique et décisif en matière de compétitivité, y compris face à des fournisseurs étrangers à la branche.
Désolidarisation des assureurs
L’un des principaux problèmes posés par les données massives aussi bien aux entreprises qu’aux individus et à la société est le risque d’une désolidarisation furtive des assureurs. À l’origine, les compagnies d’assurance étaient conçues selon le principe de solidarité: les familles ou corporations s’assuraient mutuellement contre les risques qu’un individu n’aurait pu supporter seul. Ce principe sous-tend toujours le système actuel. Selon la loi des grands nombres, plus la quantité des risques identiques croît, plus l’influence du hasard diminue. Or les données massives permettent désormais de segmenter très précisément la clientèle grâce à de nouvelles informations qui ne sont pas encore connues des assurances pour le moment. Cette possibilité n’entraîne-t-elle pas la formation de collectivités plus différenciées, plus homogènes, mais aussi plus petites? La personnalisation des primes d’assurance – par la télématique, par exemple – peut être poussée aussi loin que le permet une taille de collectif optimale, qui reste à déterminer. Celle-ci tient compte à la fois de la solidarité vis-à-vis des dommages subis par autrui, de la compensation nécessaire des risques, et du profil de risque de chaque preneur d’assurance.
Données massives et transparence
L’accès aux informations concernant la clientèle des assurances prend une nouvelle dimension avec les données massives. Elles étaient jusqu’ici fortement asymétriques et revêtaient deux visages (voir encadré 1):
- l’antisélection tout d’abord: elle diminue dans la mesure où les assureurs disposent de plus d’informations sur leurs clients et peuvent mieux évaluer leurs profils de risque;
- le risque subjectif ensuite: il diminue grâce au couplage des primes d’assurance et du comportement individuel qui progresse.
Il est vrai que, sur le marché, l’asymétrie des informations diminue grâce à l’usage croissant des nouvelles technologies. Toutefois, la transparence totale du marché n’est ni souhaitable ni même possible, surtout sur le marché des assurances. Elle signifierait, en effet, que clients et assureurs partagent la même notion de la probabilité de survenue des accidents. Or, comme les situations de risque varient nettement d’un cas à l’autre, les assureurs et clients ne les perçoivent objectivement comme identiques que de façon limitée. La transparence qu’on peut atteindre avec les données massives sera certes plus élevée, mais ne sera pas parfaite.
Les revers de la médaille d’une transparence trop élevée
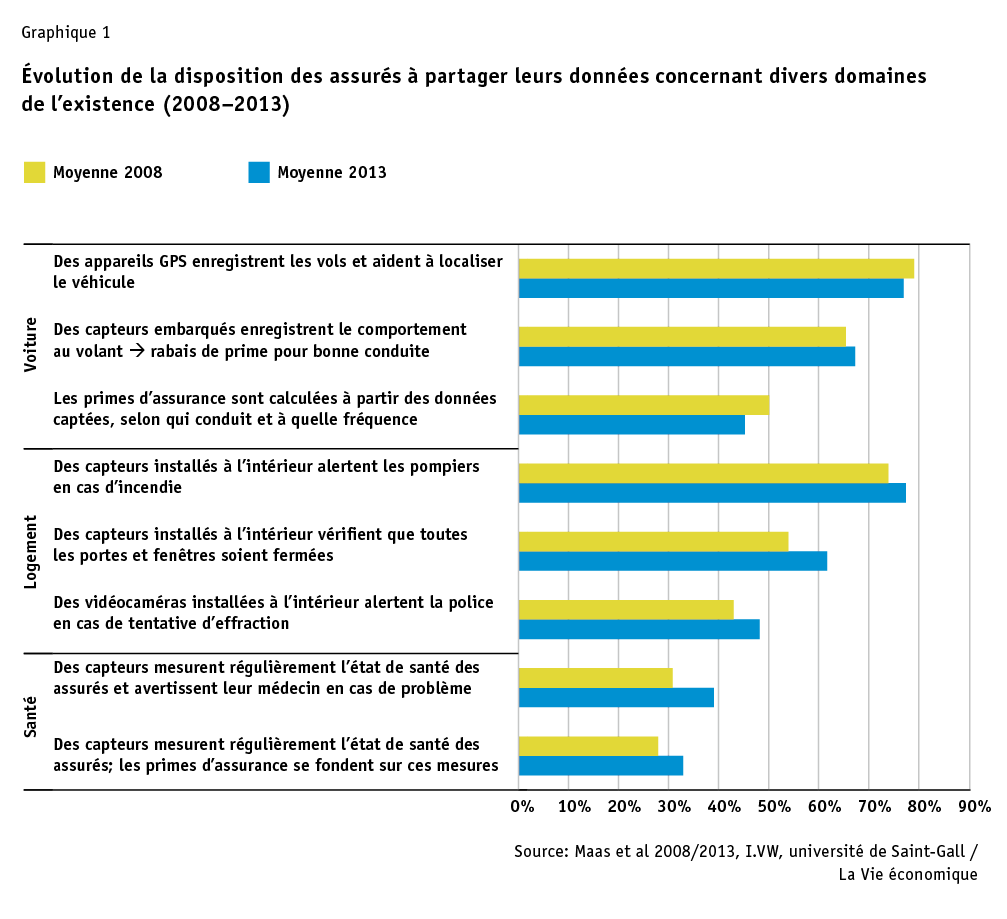
Les assureurs devront répondre franchement à toute une série de questions. La couverture d’assurance cesse-t-elle en cas de comportement fautif? Qui aura accès aux données privées collectées? Certains individus pourraient-ils être entièrement exclus de la couverture-assurance? Dans ce contexte, un facteur décisif est la disposition des clients à partager leurs données. Là encore, il semble se dessiner un changement de mentalité, à plus long terme, surtout auprès des jeunes: dans diverses études, nous avons pu montrer les situations dans lesquelles les clients sont prêts à partager leurs données personnelles avec leur compagnie d’assurance[7]. Ces cinq dernières années, on peut dire que leur disposition à le faire dans divers domaines de l’existence a foncièrement augmenté (voir graphique 1), à condition d’en retirer un avantage sensible.

- Gartner (2013).
- Mäder et al. (2014).
- Fraunhofer IAIS (2012).
- SAS Institute (2013).
- Maas et al. (2014).
- Ce terme désigne les étapes que parcourt un client avant de se décider à l’achat d’un produit.
- Maas et al. (2008), Bieck et al. (2014).







