

Les décisions quotidiennes de l’administration publique influencent l’évolution économique et sociale d’un pays. Quel est le plus sûr moyen de lutter contre l’évasion fiscale ? Quelles sont les mesures qui permettent de mieux respecter la réglementation ? Comment les entreprises réagissent-elles aux incitations fiscales ? Quand la prévention des accidents est-elle la plus efficace ?
Mesurer l’impact de telles mesures n’est en réalité pas simple. Ces dernières années, une révolution tranquille a eu lieu dans la manière d’améliorer et d’appliquer les systèmes d’analyse d’impact. De nouvelles méthodes permettent de mieux mesurer et comprendre les rapports de causalité. Les administrations publiques collaborent de plus en plus avec des scientifiques lors de l’élaboration d’études topiques, ce qui a accéléré la diffusion de ces méthodes. La combinaison de l’expérience pratique des administrations et de l’expertise méthodologique des chercheurs en sciences économiques et sociales s’avère particulièrement précieuse.
Les analyses d’impact deviennent en outre de moins en moins coûteuses grâce à la disponibilité croissante de gigantesques sources de données (« big data »). L’administration possède une vaste palette de données administratives susceptibles d’être utilisées pour mesurer l’impact de réformes et d’interventions. Il n’est dès lors plus nécessaire de procéder à des enquêtes onéreuses, ce qui réduit considérablement les coûts.
Comment mesure-t-on le « contre-fait » ?
Dans toute analyse statistique, il est crucial que la méthode choisie soit adaptée à la question analysée. Des techniques qui mesurent les rapports de causalité de façon fiable sont ainsi nécessaires pour étudier l’impact d’une réforme ou d’un programme quant à certains résultats (« outcomes »). Quel est par exemple l’effet d’une lettre de rappel sur les contribuables ? Ou quelle est l’incidence des augmentations de salaire du corps professoral sur le nombre de nouveaux enseignants ?
Plusieurs méthodes permettent de réaliser de telles analyses causales. Toutes ont en commun d’étudier les effets d’une réforme, d’un programme, d’une intervention ou d’une politique. Le principal défi réside dans le fait que l’on ne peut observer dans la réalité ce qui se serait produit en l’absence de la réforme, du programme, etc. La situation hypothétique qui se serait produite en l’absence de toute intervention est qualifiée de « contre-fait » (voir illustration).
Que se serait-il passé en l’absence de toute intervention ?
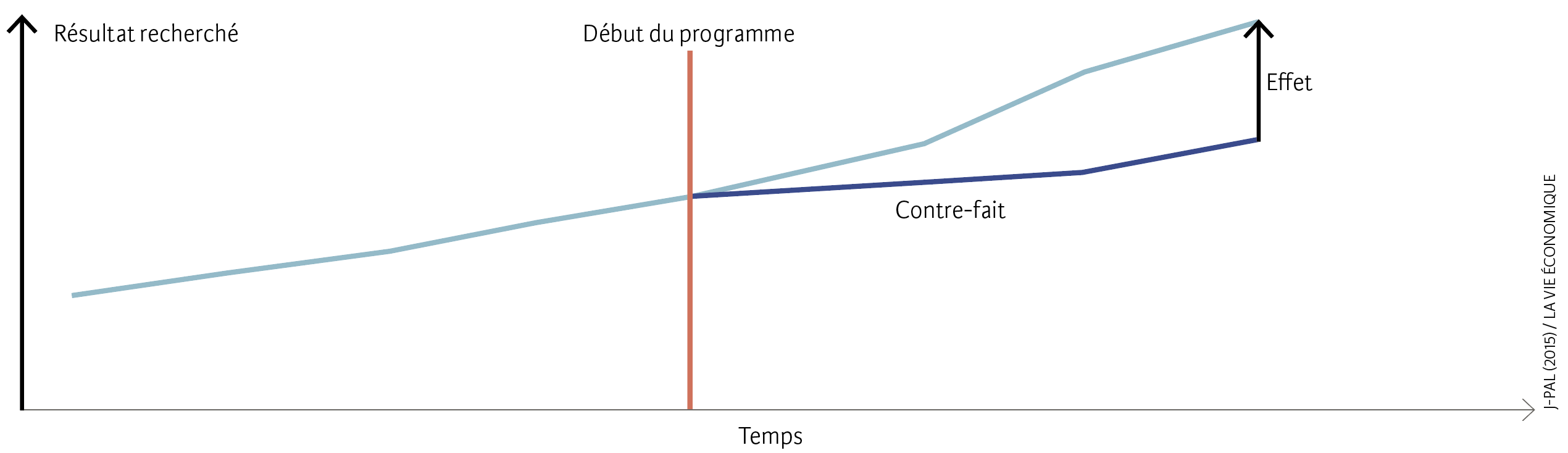
Remarque : le graphique illustre le défi principal de l’analyse d’impact, qui consiste à mesurer la différence entre le résultat réel (bleu clair) et le « contre-fait » (bleu foncé).
Source : J-PAL (2015) / La Vie économique
Comme le contre-fait ne peut pas être observé directement dans la réalité, toute analyse d’impact s’efforce – explicitement ou implicitement – de l’estimer dans la mesure du possible. Plus l’estimation est précise, plus la mesure de l’impact sera de qualité. On recourt normalement pour cela à un groupe de contrôle ou de référence[1].
Un groupe de contrôle se compose de personnes ou d’entreprises n’ayant pas été concernées par un programme ou une réforme. Pour mesurer l’impact de ces derniers, on compare les résultats du groupe affecté avec ceux du groupe de contrôle. Plus les caractéristiques des membres du groupe de contrôle coïncident avec celles des personnes affectées, plus les résultats de l’étude d’impact seront fiables. Autrement dit, si les deux groupes étaient semblables et se comportaient de manière identique avant l’intervention, la différence des résultats pourrait être attribuée au programme ou à la réforme soumis à l’évaluation.
L’autosélection fausse les résultats
Pourquoi est-il si difficile de constituer un bon groupe de référence ? Les personnes qui participent à un programme ou celles affectées par telle ou telle politique se distinguent souvent du reste de la population d’une manière qui rend la comparaison difficile. Prenons par exemple une mesure dans le domaine du chômage qui vise à améliorer les chances dans la recherche d’un emploi. Dans ce cas, on pourrait diviser l’ensemble des chômeurs en deux groupes : ceux qui décident de prendre part à la mesure proposée et ceux qui n’y participent pas.
S’il s’avère ensuite que le premier groupe retrouve plus vite un emploi, il n’est pas clair que cela soit dû à la mesure ou à d’autres raisons. Peut-être les participants étaient-ils plus motivés, d’où leur choix de participer ? Il se peut alors qu’ils aient trouvé un emploi du fait de leur plus grande motivation, et non grâce à la mesure proposée. Cette « autosélection » peut donc fausser la comparaison et entraîner des conclusions erronées.
L’étude de terrain aléatoire constitue sans doute la méthode la plus célèbre pour éviter de tels effets de sélection. Comme dans les études médicales portant sur de nouveaux médicaments, des individus, des entreprises, des classes d’école ou d’autres groupes sont exposés aléatoirement à des conditions différentes. Si la cohorte des participants est suffisamment importante, l’impact des différentes conditions peut être mesuré de façon fiable. On peut ainsi analyser l’effet de différentes lettres de rappel des autorités fiscales sur la moralité des contribuables, ou encore l’impact de mesures d’intégration sur la participation sociale et économique de personnes immigrées. Ces études de terrain aléatoires doivent être planifiées soigneusement à l’avance pour fonctionner correctement.
La régression sur discontinuité (« regression discontinuity design ») constitue une autre méthode fréquemment appliquée. Ce procédé s’utilise quand la participation à un programme ou quand l’impact d’une réforme dépend d’un seuil d’éligibilité précisément chiffré. Prenons un exemple : après le délai de remise des déclarations d’impôt, une autorité fiscale choisit de soumettre à un nouvel examen les contribuables ayant opéré plus de 15 % de déductions. Ceux qui en ont déclaré 15,1 % y sont donc soumis, contrairement à ceux qui en ont mentionné 14,9 %.
La régression sur discontinuité permet d’analyser l’impact du nouvel examen fiscal en comparant les contribuables dépassant tout juste le seuil de 15 % avec ceux qui ne l’atteignent pas de justesse. De la même manière, on pourrait mesurer l’impact d’un diplôme universitaire donné si les étudiants étaient admis à l’examen d’entrée à partir d’un certain nombre de points.
D’autres méthodes pertinentes existent, comme celle des « des différences de différences » ou « l’appariement des coefficients de propension ». Dans la première, on analyse si deux groupes analogues évoluent de façon différente après une réforme quand l’un y est soumis et l’autre pas. Dans la seconde, on constitue un groupe de contrôle « synthétique » en combinant divers groupes de référence. On peut l’appliquer par exemple lorsqu’on observe un canton donné et que l’on a besoin d’un groupe de référence, qui pourrait alors se composer d’une combinaison d’autres cantons.
Le prix Impact de la DDC
Ces méthodes causales d’évaluation se sont rapidement répandues dans le monde. Plusieurs administrations ont créé des services internes de conseil[2]. De tels efforts sont également en cours en Suisse. Ainsi, la Direction du développement et de la coopération (DDC) a introduit un prix Impact qui encourage les organisations non gouvernementales suisses à réaliser leurs propres analyses d’impact. Elle a en outre mandaté une étude externe pour examiner jusqu’où les moyens de preuve scientifiques pourraient être inclus et renforcés à la DDC[3].
Plusieurs entreprises et organisations internationales réalisent elles aussi des analyses d’impact pour fonder leur action sur les meilleures bases possible. Elles peuvent également apprendre beaucoup des études déjà existantes dans d’autres pays. Le réseau de recherche « Poverty action lab » (J-PAL), qui se concentre sur la lutte contre la pauvreté au sens large, met par exemple des centaines d’analyses à disposition sur son site Internet. Des organisations spécialisées qui aident les autorités et les organisations à constituer et à exploiter les moyens de preuve ont par ailleurs émergé. Mentionnons par exemple « Evidence action » au niveau international et « Policy analytics » en Suisse.
La nouvelle révolution empirique constitue donc une chance immense pour le secteur public. Les nouveaux outils permettent aux institutions de fonder leurs décisions sur des bases de plus en plus fiables qui s’appuient sur des éléments probants. Il faut s’attendre à ce que cette tendance se renforce ces prochaines années, à mesure que la disponibilité des données et l’expertise dans le maniement des nouvelles méthodes continueront d’augmenter.

- Voir Pomeranz (2017).
- Voir Pomeranz et Vila-Belda (2019).
- Roquet et al. (2017).







